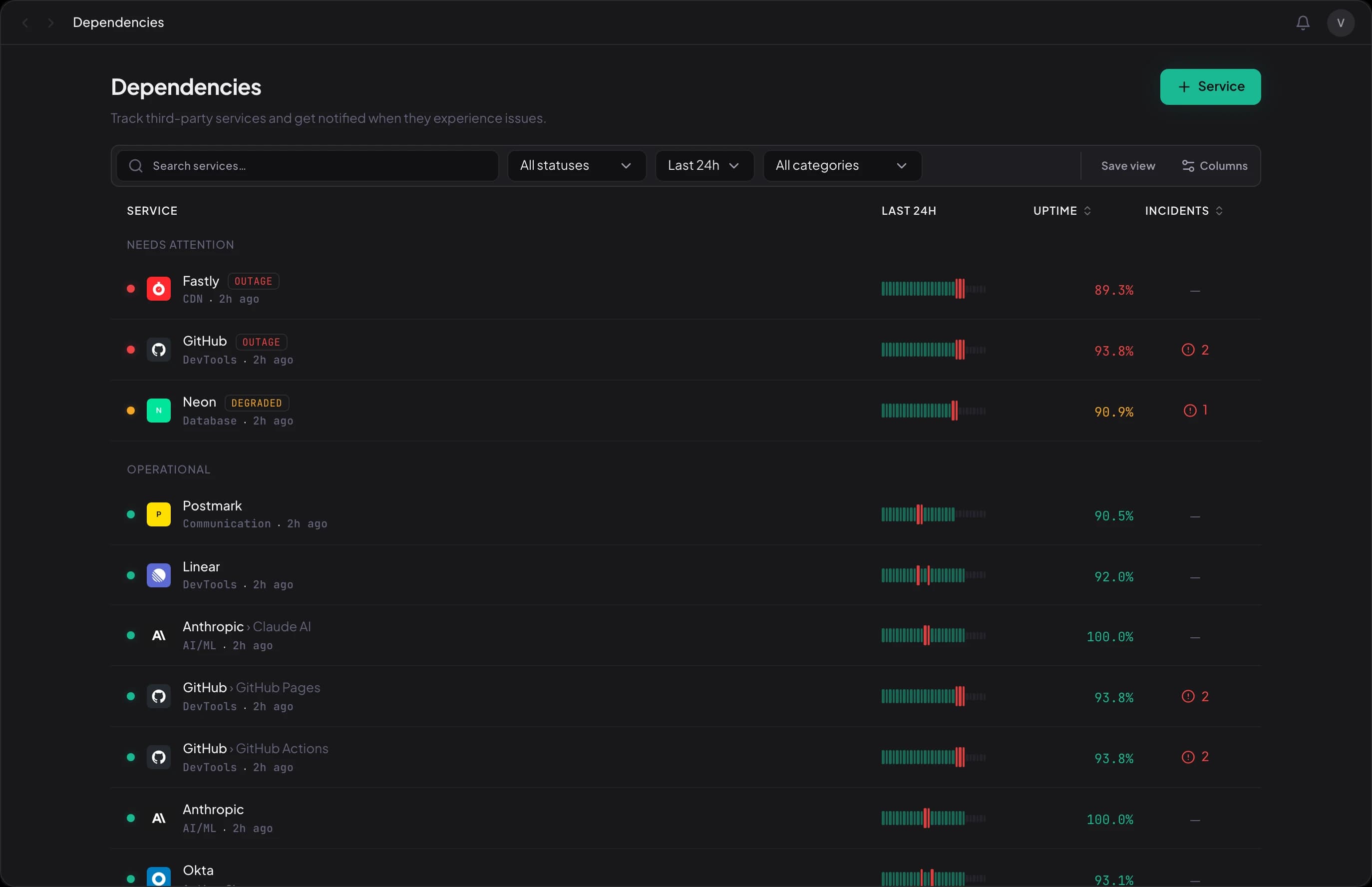
Detect External Service Failures. Instantly.
DevHelm tracks 80+ services your stack depends on. When an upstream provider degrades, we correlate it with your monitors — one alert with full context, not 47 separate notifications.
When Stripe Goes Down, You Get 47 Alerts.
Your checkout endpoint times out. Your billing service throws 500s. Your webhook processor backs up. Your team scrambles across three Slack channels trying to figure out if it's your code, your database, or something else entirely.
One upstream outage triggers alerts for every downstream service. Your on-call engineer gets paged 12 times before they can even open a laptop.
Is it your code? Your database? Your CDN? Without knowing that Stripe is degraded, your team spends 30 minutes investigating the wrong thing.
Without automatic correlation, root cause identification is manual. You check each vendor status page individually, cross-reference timestamps, and hope you don't miss one.
From Status Page to Root Cause. Automatically.
DevHelm continuously polls 80+ provider status pages, detects degradation, and correlates it with your monitors in real time. No configuration required.
We continuously poll 80+ vendor status pages, APIs, and health endpoints. Zero config on your end.
When a provider reports degradation or downtime, we detect it within seconds and classify the impact level.
We link the upstream issue to your monitors and resource groups. One alert with full context — not a flood.
What This Looks Like At 3am.
Three real scenarios where dependency intelligence changes how your team responds to incidents.
Your team would normally get 23 separate alerts for each microservice on us-east-1. With DevHelm: one alert — "AWS us-east-1 is experiencing elevated error rates. 23 monitors in your Production resource group are affected."
23 alerts → 1 root causeYour checkout endpoint starts timing out. Is it your code? Your database? DevHelm correlates: "Stripe API is reporting elevated latency. Your checkout and billing endpoints are affected. No issues with your internal infrastructure."
Instant root cause identificationUsers can't log in. Your API health checks pass. DevHelm identifies: "Auth0 is experiencing a partial outage. Your login and registration flows are impacted. No issues with your internal services."
Know before users report80+ Services. Zero Config.
We poll the status of the most popular infrastructure, payment, auth, and developer services continuously — so you don't have to check each vendor page manually.
...and 70+ more including AWS, Google Cloud, Azure, Shopify, SendGrid, Slack, MongoDB Atlas, and more.
Included From Day One.
Dependency intelligence isn't a premium add-on. Every DevHelm account gets it — including Free. No setup, no configuration, no extra cost.
Know the Root Cause. Instantly.
50 free monitors with dependency intelligence built in. No credit card required.
Start Monitoring Free